When working with textual data and trying to classify text into different languages, which approach to representing features makes the most sense?
Which of the following is the correct definition of the quality criteria that describes completeness?
Your dependent variable data is a proportion. The observed range of your data is 0.01 to 0.99. The instrument used to generate the dependent variable data is known to generate low quality data for values close to 0 and close to 1. A colleague suggests performing a logit-transformation on the data prior to performing a linear regression. Which of the following is a concern with this approach?
Definition of logit-transformation
If p is the proportion: logit(p)=log(p/(l-p))
Which two of the following criteria are essential for machine learning models to achieve before deployment? (Select two.)
You create a prediction model with 96% accuracy. While the model's true positive rate (TPR) is performing well at 99%, the true negative rate (TNR) is only 50%. Your supervisor tells you that the TNR needs to be higher, even if it decreases the TPR. Upon further inspection, you notice that the vast majority of your data is truly positive.
What method could help address your issue?
You are implementing a support-vector machine on your data, and a colleague suggests you use a polynomial kernel. In what situation might this help improve the prediction of your model?
You have a dataset with thousands of features, all of which are categorical. Using these features as predictors, you are tasked with creating a prediction model to accurately predict the value of a continuous dependent variable. Which of the following would be appropriate algorithms to use? (Select two.)
In which of the following scenarios is lasso regression preferable over ridge regression?
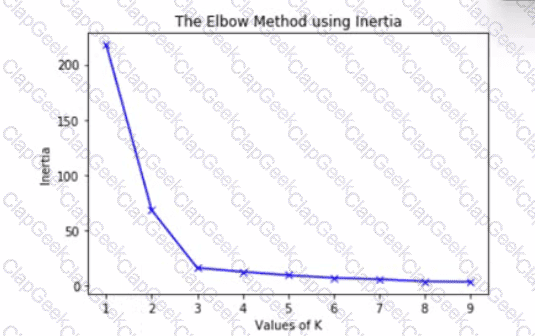
The graph is an elbow plot showing the inertia or within-cluster sum of squares on the y-axis and number of clusters (also called K) on the x-axis, denoting the change in inertia as the clusters change using k-means algorithm.
What would be an optimal value of K to ensure a good number of clusters?
Given a feature set with rows that contain missing continuous values, and assuming the data is normally distributed, what is the best way to fill in these missing features?
A product manager is designing an Artificial Intelligence (AI) solution and wants to do so responsibly, evaluating both positive and negative outcomes.
The team creates a shared taxonomy of potential negative impacts and conducts an assessment along vectors such as severity, impact, frequency, and likelihood.
Which modeling technique does this team use?
Which of the following tests should be performed at the production level before deploying a newly retrained model?
Which two of the following statements about the beta value in an A/B test are accurate? (Select two.)
What is the open framework designed to help detect, respond to, and remediate threats in ML systems?
Which of the following approaches is best if a limited portion of your training data is labeled?
Which two encodes can be used to transform categories data into numerical features? (Select two.)
Which of the following regressions will help when there is the existence of near-linear relationships among the independent variables (collinearity)?
Which of the following sentences is TRUE about the definition of cloud models for machine learning pipelines?




TESTED 25 Jun 2026