You need to configure a sink connector to write records that fail into a dead letter queue topic. Requirements:
Topic name: DLQ-Topic
Headers containing error context must be added to the messagesWhich three configuration parameters are necessary?(Select three.)
Which configuration determines how many bytes of data are collected before sending messages to the Kafka broker?
(You deploy a Kafka Streams application with five application instances.
Kafka Streams stores application metadata using internal topics.
Auto-topic creation is disabled in the Kafka cluster.
Which statement about this scenario is true?)
(An S3 source connector named s3-connector stopped running.
You use the Kafka Connect REST API to query the connector and task status.
One of the three tasks has failed.
You need to restart the connector and all currently running tasks.
Which REST request will restart the connector instance and all its tasks?)
You create a topic named stream-logs with:
A replication factor of 3
Four partitions
Messages that are plain logs without a keyHow will messages be distributed across partitions?
(You are building real-time streaming applications using Kafka Streams.
Your application has a custom transformation.
You need to define custom processors in Kafka Streams.
Which tool should you use?)
You are experiencing low throughput from a Java producer.
Metrics show low I/O thread ratio and low I/O thread wait ratio.
What is the most likely cause of the slow producer performance?
The producer code below features a Callback class with a method called onCompletion().
In the onCompletion() method, when the request is completed successfully, what does the value metadata.offset() represent?
(You have a topic with four partitions. The application reading this topic is using a consumer group with two consumers.
Throughput is smoothly distributed among partitions, but application lag is increasing.
Application monitoring shows that message processing is consuming all available CPU resources.
Which action should you take to resolve this issue?)
(You want to enrich the content of a topic by joining it with key records from a second topic.
The two topics have a different number of partitions.
Which two solutions can you use?
Select two.)
You are working on a Kafka cluster with three nodes. You create a topic named orders with:
replication.factor = 3
min.insync.replicas = 2
acks = allWhat exception will be generated if two brokers are down due to network delay?
Which two statements about Kafka Connect Single Message Transforms (SMTs) are correct?
(Select two.)
You have a topic t1 with six partitions. You use Kafka Connect to send data from topic t1 in your Kafka cluster to Amazon S3. Kafka Connect is configured for two tasks.
How many partitions will each task process?
You are writing to a topic with acks=all.
The producer receives acknowledgments but you notice duplicate messages.
You find that timeouts due to network delay are causing resends.
Which configuration should you use to prevent duplicates?
(Which configuration is valid for deploying a JDBC Source Connector to read all rows from the orders table and write them to the dbl-orders topic?)
You want to connect with username and password to a secured Kafka cluster that has SSL encryption.
Which properties must your client include?
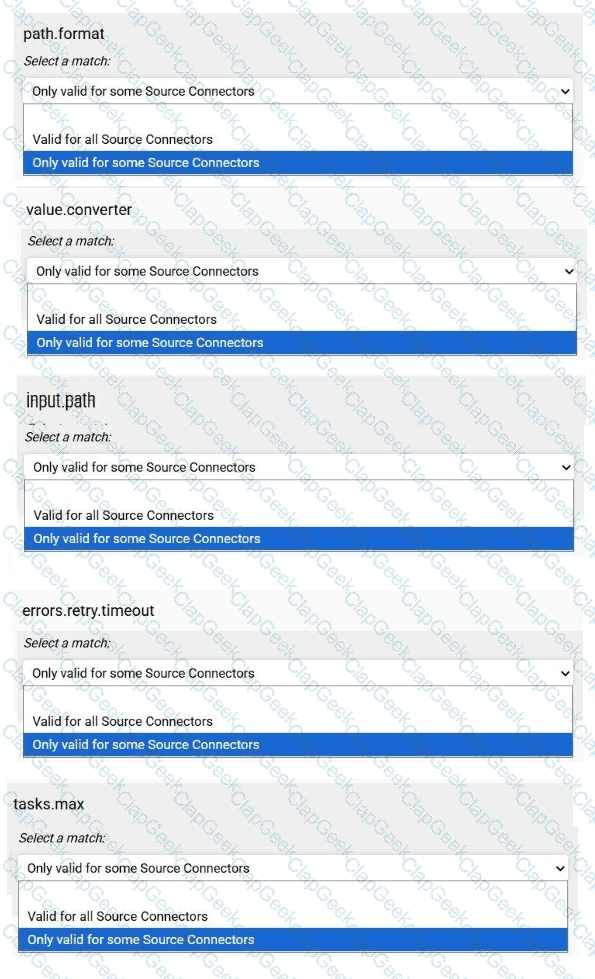
Match each configuration parameter with the correct option.
To answer choose a match for each option from the drop-down. Partial
credit is given for each correct answer.
You have a topic with four partitions. The application reads from it using two consumers in a single consumer group.
Processing is CPU-bound, and lag is increasing.
What should you do?
You need to explain the best reason to implement the consumer callback interface ConsumerRebalanceListener prior to a Consumer Group Rebalance.
Which statement is correct?
(A consumer application needs to use an at-most-once delivery semantic.
What is the best consumer configuration and code skeleton to avoid duplicate messages being read?)
You have a Kafka Connect cluster with multiple connectors.
One connector is not working as expected.
How can you find logs related to that specific connector?




TESTED 14 Mar 2026

