A governance team is evaluating whether to use Unity Catalog attribute-based access control policies or manually applied row filters and column masks to protect sensitive data across its catalog.
Why should the team use attribute-based access control policies instead of manually applied row filters and column masks?
A Python file is ready to go into production and the client wants to use the cheapest but most efficient type of cluster possible. The workload is quite small, only processing 10GBs of data with only simple joins and no complex aggregations or wide transformations.
Which cluster meets the requirement?
A data engineer needs access to a table new_table, but they do not have the correct permissions. They can ask the table owner for permission, but they do not know who the table owner is.
Which of the following approaches can be used to identify the owner of new_table?
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > ' 2020-01-01 ' ) ON VIOLATION FAIL UPDATE
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
A data engineer needs to conduct Exploratory Data Analysis (EDA) on data residing in a database within the company’s custom-defined cloud network . The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
Which compute option should be chosen in a scenario where small-scale ad hoc Python scripts need to be run at high frequency and should wind down quickly after these queries have finished running?
A data engineer has a Python variable table_name that they would like to use in a SQL query. They want to construct a Python code block that will run the query using table_name.
They have the following incomplete code block:
____(f " SELECT customer_id, spend FROM {table_name} " )
Which of the following can be used to fill in the blank to successfully complete the task?
A new data engineering team team has been assigned to an ELT project. The new data engineering team will need full privileges on the table sales to fully manage the project.
Which of the following commands can be used to grant full permissions on the database to the new data engineering team?
A Databricks workflow fails at the last stage due to an error in a notebook. This workflow runs daily. The data engineer fixes the mistake and wants to rerun the pipeline. This workflow is very costly and time-intensive to run.
Which action should the data engineer do in order to minimise downtime and cost?
A data engineer has a Declarative Automation Bundle with a job resource keyed as etl_job in databricks.yml. After running databricks bundle deploy, the job appears in the workspace but has not executed.
Which command triggers execution of the deployed job?
Which SQL code snippet will correctly demonstrate a Data Definition Language (DDL) operation used to create a table?
What is the maximum output supported by a job cluster to ensure a notebook does not fail?
Which of the following describes the relationship between Gold tables and Silver tables?
A data engineer needs to migrate the Unity Catalog external Delta table catalog.schema.sales while meeting the following requirements:
Databricks must manage file cleanup after the table is dropped.
The migration must minimize downtime while retaining the same table name, permissions, and history.
Access must be enforced through the registered Unity Catalog table name.
Which action should the engineer take?
A data engineer has a Job with multiple tasks that runs nightly. Each of the tasks runs slowly because the clusters take a long time to start.
Which of the following actions can the data engineer perform to improve the start up time for the clusters used for the Job?
Identify how the count_if function and the count where x is null can be used
Consider a table random_values with below data.
What would be the output of below query?
select count_if(col > 1) as count_a. count(*) as count_b.count(col1) as count_c from random_values col1
0
1
2
NULL -
2
3
A data engineer is designing a cost-optimized, event-driven pipeline. They configure a Lakeflow Job with a File Arrival trigger to watch an Amazon S3 bucket. The job runs a notebook that uses Auto Loader with trigger(availableNow=True) to ingest data into a Bronze table.
What is the technical relationship between the File Arrival trigger and Auto Loader in this integration pattern?
A data engineer is standardizing repository layouts for multiple teams adopting Databricks Asset Bundles. The engineer wants to ensure every project has a single authoritative configuration file at the repository root that defines the bundle name, targets, workspace settings, permissions, and resource mappings (for jobs and pipelines).
Which strategy should the data engineer use to meet this goal?
A data engineer has realized that the data files associated with a Delta table are incredibly small. They want to compact the small files to form larger files to improve performance.
Which of the following keywords can be used to compact the small files?
A data engineer is designing an ETL pipeline to process both streaming and batch data from multiple sources The pipeline must ensure data quality, handle schema evolution, and provide easy maintenance. The team is considering using Delta Live Tables (DLT) in Databricks to achieve these goals. They want to understand the key features and benefits of DLT that make it suitable for this use case.
Why is Delta Live Tables (DLT) an appropriate choice?
A data analysis team has noticed that their Databricks SQL queries are running too slowly when connected to their always-on SQL endpoint. They claim that this issue is present when many members of the team are running small queries simultaneously. They ask the data engineering team for help. The data engineering team notices that each of the team’s queries uses the same SQL endpoint.
Which of the following approaches can the data engineering team use to improve the latency of the team’s queries?
In which of the following scenarios should a data engineer use the MERGE INTO command instead of the INSERT INTO command?
A data engineer wants to schedule their Databricks SQL dashboard to refresh once per day, but they only want the associated SQL endpoint to be running when it is necessary.
Which of the following approaches can the data engineer use to minimize the total running time of the SQL endpoint used in the refresh schedule of their dashboard?
A data engineer wants to create a relational object by pulling data from two tables. The relational object does not need to be used by other data engineers in other sessions. In order to save on storage costs, the data engineer wants to avoid copying and storing physical data.
Which of the following relational objects should the data engineer create?
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job’s current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
A data engineer only wants to execute the final block of a Python program if the Python variable day_of_week is equal to 1 and the Python variable review_period is True.
Which of the following control flow statements should the data engineer use to begin this conditionally executed code block?
A data engineer has developed a data pipeline to ingest data from a JSON source using Auto Loader, but the engineer has not provided any type inference or schema hints in their pipeline. Upon reviewing the data, the data engineer has noticed that all of the columns in the target table are of the string type despite some of the fields only including float or boolean values.
Which of the following describes why Auto Loader inferred all of the columns to be of the string type?
A data engineer wants to reduce costs and optimize cloud spending. The data engineer has decided to use Databricks Serverless for lowering cloud costs while maintaining existing SLAs.
What is the first step in migrating to Databricks Serverless?
A departing platform owner currently holds ownership of multiple catalogs and controls storage credentials and external locations. The data engineer wants to ensure continuity: transfer catalog ownership to the platform team group, delegate ongoing privilege management, and retain the ability to receive and share data via Delta Sharing .
Which role must be in place to perform these actions across the metastore?
What Databricks feature can be used to check the data sources and tables used in a workspace?
A data engineering team needs to integrate two data sources into Databricks:
Clickstream events: 5,000 events per second from an Apache Kafka topic
Customer master data: Only changed records every four hours from a Snowflake database
The solution must process clickstream data with latency under 30 seconds and prevent reprocessing customer master data that has not changed.
Which ingestion approach meets these requirements?
A data engineer needs to optimize the data layout and query performance for an e-commerce transactions Delta table. The table is partitioned by " purchase_date " a date column which helps with time-based queries but does not optimize searches on user statistics " customer_id " , a high-cardinality column.
The table is usually queried with filters on " customer_i
d " within specific date ranges, but since this data is spread across multiple files in each partition, it results in full partition scans and increased runtime and costs.
How should the data engineer optimize the Data Layout for efficient reads?
Identify the impact of ON VIOLATION DROP ROW and ON VIOLATION FAIL UPDATE for a constraint violation.
A data engineer has created an ETL pipeline using Delta Live table to manage their company travel reimbursement detail, they want to ensure that the if the location details has not been provided by the employee, the pipeline needs to be terminated.
How can the scenario be implemented?
A data engineer has realized that they made a mistake when making a daily update to a table. They need to use Delta time travel to restore the table to a version that is 3 days old. However, when the data engineer attempts to time travel to the older version, they are unable to restore the data because the data files have been deleted.
Which of the following explains why the data files are no longer present?
A Data Engineer is building a simple data pipeline using Delta Live Tables (DLT) in Databricksto ingest customer data. The raw customer data is stored in a cloud storage location in JSON format. The task is to create a DLT pipeline that reads the rawJSON data and writes it into a Delta table for further processing.
Which code snippet will correctly ingest the raw JSON data and create a Delta table using DLT?
A)

B)

C)

D)

A data engineer needs to combine sales data from an on-premises PostgreSQL database with customer data in Azure Synapse for a comprehensive report. The goal is to avoid data duplication and ensure up-to-date information
How should the data engineer achieve this using Databricks?
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
Which method should a Data Engineer apply to ensure Workflows are being triggered on schedule?
A data engineer ingests semi-structured JSON logs into a Delta table using Auto Loader with schema evolution enabled. A new string field named userAgent appears in the JSON source data.
What happens to the new userAgent field?
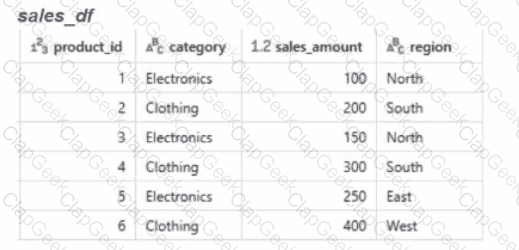
Calculate the total sales amount for each region and store the results in a new dataframe called region_sales.
Given the expected result:

Which code will generate the expected result?
A developer is building a data pipeline that processes records from a Bronze table into a Silver table. The Bronze table, bronze_events, contains duplicate records because of at-least-once delivery guarantees from the upstream ingestion system. The developer writes the following PySpark code:
deduped_df = df.dropDuplicates()
deduped_df.summary( " count " , " mean " , " stddev " ).show()
from pyspark.sql.functions import approx_count_distinct
deduped_df.select(approx_count_distinct( " user_id " )).show()
After running dropDuplicates() without arguments, some rows that differ only in the event_timestamp column remain. The developer wants to deduplicate records based only on user_id and event_type, keeping one row for each unique combination of those two columns.
Which code change achieves this deduplication requirement?
A data engineer is decommissioning a sandbox schema in Unity Catalog. Some tables are ephemeral staging outputs that can be safely removed entirely, but a few tables point at shared cloud storage used by downstream jobs outside Databricks. The engineer must avoid deleting any shared files when cleaning up catalog objects.
How does Unity Catalog behave when dropping Managed vs External tables?
An organization is building a data lakehouse and needs to ingest data from multiple sources into Unity Catalog-managed tables:
Salesforce: More than 50 objects, frequent schema changes, and OAuth authentication
An on-premises SQL Server database: More than 100 tables, CDC enabled, and private network connectivity required
Daily JSON files landing in Azure Data Lake Storage Gen2
The organization wants all ingested data governed by Unity Catalog, minimal engineering effort for schema changes, and serverless processing wherever possible.
Which ingestion strategy meets these requirements?
A data engineer needs to provide access to a group named manufacturing-team. The team needs privileges to create tables in the quality schema.
Which set of SQL commands will grant a group named manufacturing-team to create tables in a schema named production with the parent catalog named manufacturing with the least privileges?
A)

B)

C)

D)

A data engineer has manually created several Databricks jobs and dashboards using the workspace UI. The team now wants to manage these resources as code using Declarative Automation Bundles, formerly known as Databricks Asset Bundles, store the configuration in a Git repository, and deploy changes through CI/CD.
Which approach converts the existing resources into a bundle project?
A data engineer needs to create a table in Databricks using data from their organization’s existing SQLite database.
They run the following command:
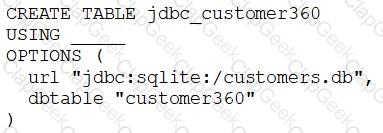
Which of the following lines of code fills in the above blank to successfully complete the task?
A data engineer has been using a Databricks SQL dashboard to monitor the cleanliness of the input data to a data analytics dashboard for a retail use case. The job has a Databricks SQL query that returns the number of store-level records where sales is equal to zero. The data engineer wants their entire team to be notified via a messaging webhook whenever this value is greater than 0.
Which of the following approaches can the data engineer use to notify their entire team via a messaging webhook whenever the number of stores with $0 in sales is greater than zero?
A data engineer that is new to using Python needs to create a Python function to add two integers together and return the sum?
Which of the following code blocks can the data engineer use to complete this task?
A)
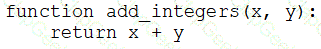
B)

C)
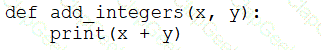
D)
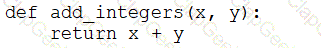
E)
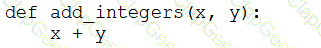
A data engineer is maintaining an ETL pipeline code with a GitHub repository linked to their Databricks account. The data engineer wants to deploy the ETL pipeline to production as a databricks workflow.
Which approach should the data engineer use?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which change will need to be made to the pipeline when migrating to Delta Live Tables?
An organization has data stored across multiple external systems, including MySQL, Amazon Redshift, and Google BigQuery. The data engineer wants to perform analytics without ingesting data directly into Databricks, while ensuring unified governance and minimizing data duplication.
Which feature of Databricks enables querying these external data sources while maintaining centralized governance?
In which of the following scenarios should a data engineer select a Task in the Depends On field of a new Databricks Job Task?
A data engineer is transforming a Bronze table containing API-response data into a Silver table. The Bronze table has a user_profile column of type STRING that contains JSON data. An example value is:
{ " user_id " : " 12345 " , " name " : " John Smith " , " age " :32, " email " : " john@example.com " }
The Silver table must make this data easily queryable for analytics without requiring JSON parsing in every downstream query.
Which approach standardizes this column for the Silver table?
Which two components function in the DB platform architecture’s control plane? (Choose two.)
A company is collaborating with a partner that does not use Databricks but needs access to a large historical dataset stored in Delta format. The data engineer needs to ensure that the partner can access the data securely, without the need for them to set up an account, and with read-only access.
How should the data be shared?
A data engineer runs df.toPandas() on a wide DataFrame containing 50 million rows. The notebook cell fails with a java.lang.OutOfMemoryError on the driver.
Which memory configuration is directly associated with this failure?
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
Identify a scenario to use an external table.
A Data Engineer needs to create a parquet bronze table and wants to ensure that it gets stored in a specific path in an external location.
Which table can be created in this scenario?
A data engineering team needs to ingest historical CSV files from a cloud-storage location that already contains 50,000 existing files. The team also expects new files to arrive continuously. The team wants to use Auto Loader to incrementally process both the existing files and new arrivals efficiently.
Which Auto Loader mode should the team configure for this use case?
Which Databricks SQL predicate correctly performs a null-safe equality comparison so that rows are matched when both sides are NULL or when both are equal non-NULL values?
A data engineer is setting up access control in Unity Catalog and needs to ensure that a group of data analysts can query tables but not modify data.
Which permission should the data engineer grant to the data analysts?
Which query is performing a streaming hop from raw data to a Bronze table?
A)

B)

C)

D)





TESTED 29 Jul 2026