You are creating a CI/CD pipeline to perform Terraform deployments of Google Cloud resources Your CI/CD tooling is running in Google Kubernetes Engine (GKE) and uses an ephemeral Pod for each pipeline run You must ensure that the pipelines that run in the Pods have the appropriate Identity and Access Management (1AM) permissions to perform the Terraform deployments You want to follow Google-recommended practices for identity management What should you do?
Choose 2 answers
You are deploying an application that needs to access sensitive information. You need to ensure that this information is encrypted and the risk of exposure is minimal if a breach occurs. What should you do?
Your company operates in a highly regulated domain. Your security team requires that only trusted container images can be deployed to Google Kubernetes Engine (GKE). You need to implement a solution that meets the requirements of the security team, while minimizing management overhead. What should you do?
You are building the Cl/CD pipeline for an application deployed to Google Kubernetes Engine (GKE) The application is deployed by using a Kubernetes Deployment, Service, and Ingress The application team asked you to deploy the application by using the blue'green deployment methodology You need to implement the rollback actions What should you do?
You need to enforce several constraint templates across your Google Kubernetes Engine (GKE) clusters. The constraints include policy parameters, such as restricting the Kubernetes API. You must ensure that the policy parameters are stored in a GitHub repository and automatically applied when changes occur. What should you do?
Your team is preparing to launch a new API in Cloud Run. The API uses an OpenTelemetry agent to send distributed tracing data to Cloud Trace to monitor the time each request takes. The team has noticed inconsistent trace collection. You need to resolve the issue. What should you do?
You are deploying an application to Cloud Run. The application requires a password to start. Your organization requires that all passwords are rotated every 24 hours, and your application must have the latest password. You need to deploy the application with no downtime. What should you do?
You have an application deployed to Cloud Run. A new version of the application has recently been deployed using the canary deployment strategy. Your Site Reliability Engineering (SRE) teammate informs you that an SLO has been exceeded for this application. You need to make the application healthy as quickly as possible. What should you do first?
Your company processes IOT data at scale by using Pub/Sub, App Engine standard environment, and an application written in GO. You noticed that the performance inconsistently degrades at peak load. You could not reproduce this issue on your workstation. You need to continuously monitor the application in production to identify slow paths in the code. You want to minimize performance impact and management overhead. What should you do?
Your company operates in a highly regulated domain that requires you to store all organization logs for seven years You want to minimize logging infrastructure complexity by using managed services You need to avoid any future loss of log capture or stored logs due to misconfiguration or human error What should you do?
You are running an application on Compute Engine and collecting logs through Stackdriver. You discover that some personally identifiable information (Pll) is leaking into certain log entry fields. All Pll entries begin with the text userinfo. You want to capture these log entries in a secure location for later review and prevent them from leaking to Stackdriver Logging. What should you do?
Your organization wants to implement Site Reliability Engineering (SRE) culture and principles. Recently, a service that you support had a limited outage. A manager on another team asks you to provide a formal explanation of what happened so they can action remediations. What should you do?
Your application services run in Google Kubernetes Engine (GKE). You want to make sure that only images from your centrally-managed Google Container Registry (GCR) image registry in the altostrat-images project can be deployed to the cluster while minimizing development time. What should you do?
Your team is running microservices in Google Kubernetes Engine (GKE) You want to detect consumption of an error budget to protect customers and define release policies What should you do?
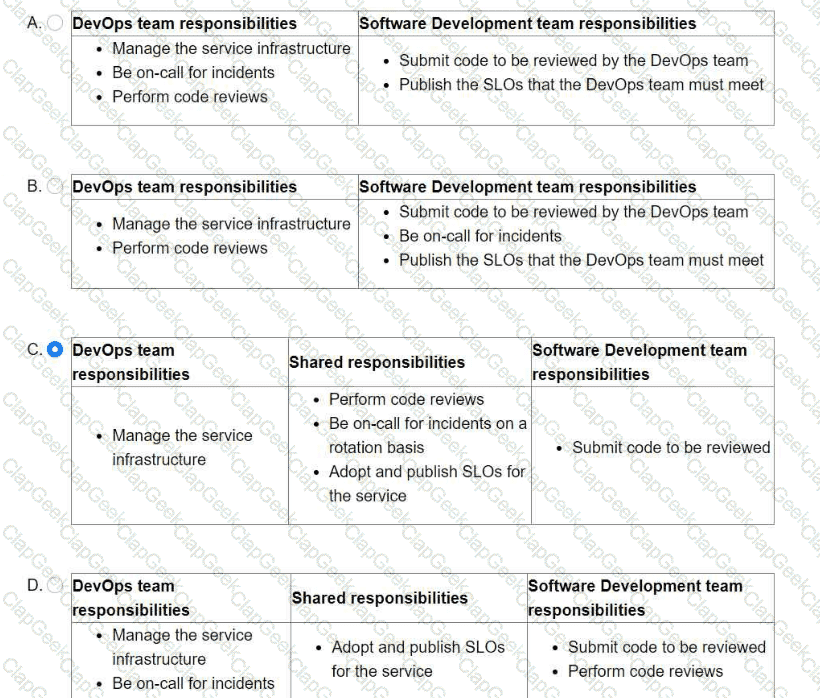
You are leading a DevOps project for your organization. The DevOps team is responsible for managing the service infrastructure and being on-call for incidents. The Software Development team is responsible for writing, submitting, and reviewing code. Neither team has any published SLOs. You want to design a new joint-ownership model for a service between the DevOps team and the Software Development team. Which responsibilities should be assigned to each team in the new joint-ownership model?
You are developing a Node.js utility on a workstation in Cloud Workstations by using Code OSS. The utility is a simple web page, and you have already confirmed that all necessary firewall rules are in place. You tested the application by starting it on port 3000 on your workstation in Cloud Workstations, but you need to be able to access the web page from your local machine. You need to follow Google-recommended security practices. What should you do?
You support a user-facing web application. When analyzing the application’s error budget over the previous six months, you notice that the application has never consumed more than 5% of its error budget in any given time window. You hold a Service Level Objective (SLO) review with business stakeholders and confirm that the SLO is set appropriately. You want your application’s SLO to more closely reflect its observed reliability. What steps can you take to further that goal while balancing velocity, reliability, and business needs? (Choose two.)
You are designing a continuous delivery (CD) strategy for a new serverless application. The application is packaged as a container image, stored in Artifact Registry, and deployed to Cloud Run. Your design requires a staging environment, a fully-managed Google Cloud service, mandatory manual approval for production deployments, and a phased rollout to production. Your solution should minimize administrative overhead. What should you do?
You are responsible for the reliability of a high-volume enterprise application. A large number of users report that an important subset of the application’s functionality – a data intensive reporting feature – is consistently failing with an HTTP 500 error. When you investigate your application’s dashboards, you notice a strong correlation between the failures and a metric that represents the size of an internal queue used for generating reports. You trace the failures to a reporting backend that is experiencing high I/O wait times. You quickly fix the issue by resizing the backend’s persistent disk (PD). How you need to create an availability Service Level Indicator (SLI) for the report generation feature. How would you define it?
You are using Terraform to manage infrastructure as code within a Cl/CD pipeline You notice that multiple copies of the entire infrastructure stack exist in your Google Cloud project, and a new copy is created each time a change to the existing infrastructure is made You need to optimize your cloud spend by ensuring that only a single instance of your infrastructure stack exists at a time. You want to follow Google-recommended practices What should you do?
Your company runs an ecommerce website built with JVM-based applications and microservice architecture in Google Kubernetes Engine (GKE) The application load increases during the day and decreases during the night Your operations team has configured the application to run enough Pods to handle the evening peak load You want to automate scaling by only running enough Pods and nodes for the load What should you do?
Your company runs applications in Google Kubernetes Engine (GKE). Several applications rely on ephemeral volumes. You noticed some applications were unstable due to the DiskPressure node condition on the worker nodes. You need
to identify which Pods are causing the issue, but you do not have execute access to workloads and nodes. What should you do?
You are running an experiment to see whether your users like a new feature of a web application. Shortly after deploying the feature as a canary release, you receive a spike in the number of 500 errors sent to users, and your monitoring reports show increased latency. You want to quickly minimize the negative impact on users. What should you do first?
Your company runs services by using multiple globally distributed Google Kubernetes Engine (GKE) clusters Your operations team has set up workload monitoring that uses Prometheus-based tooling for metrics alerts: and generating dashboards This setup does not provide a method to view metrics globally across all clusters You need to implement a scalable solution to support global Prometheus querying and minimize management overhead What should you do?
You are running an application in a virtual machine (VM) using a custom Debian image. The image has the Stackdriver Logging agent installed. The VM has the cloud-platform scope. The application is logging information via syslog. You want to use Stackdriver Logging in the Google Cloud Platform Console to visualize the logs. You notice that syslog is not showing up in the "All logs" dropdown list of the Logs Viewer. What is the first thing you should do?
You have deployed a fleet Of Compute Engine instances in Google Cloud. You need to ensure that monitoring metrics and logs for the instances are visible in Cloud Logging and Cloud Monitoring by your company's operations and cyber
security teams. You need to grant the required roles for the Compute Engine service account by using Identity and Access Management (IAM) while following the principle of least privilege. What should you do?
Your company is migrating its production systems to Google Cloud. You need to implement site reliability engineering (SRE) practices during the migration to minimize customer impact from potential future incidents. Which two SRE practices should you implement?
Choose 2 answers
You are running a web application that connects to an AlloyDB cluster by using a private IP address in your default VPC. You need to run a database schema migration in your CI/CD pipeline by using Cloud Build before deploying a new version of your application. You want to follow Google-recommended security practices. What should you do?
Your organization is using Helm to package containerized applications Your applications reference both public and private charts Your security team flagged that using a public Helm repository as a dependency is a risk You want to manage all charts uniformly, with native access control and VPC Service Controls What should you do?
As a Site Reliability Engineer, you support an application written in GO that runs on Google Kubernetes Engine (GKE) in production. After releasing a new version Of the application, you notice the applicationruns for about 15 minutes and then restarts. You decide to add Cloud Profiler to your application and now notice that the heap usage grows constantly until the application restarts. What should you do?
Your company is using HTTPS requests to trigger a public Cloud Run-hosted service accessible at the https://booking-engine-abcdef .a.run.app URL You need to give developers the ability to test the latest revisions of the service before the service is exposed to customers What should you do?
You are using Stackdriver to monitor applications hosted on Google Cloud Platform (GCP). You recently deployed a new application, but its logs are not appearing on the Stackdriver dashboard.
You need to troubleshoot the issue. What should you do?
You need to introduce postmortems into your organization. You want to ensure that the postmortem process is well received. What should you do?
Choose 2 answers
Your company uses a CI/CD pipeline with Cloud Build and Artifact Registry to deploy container images to Google Kubernetes Engine (GKE). Images are tagged with the latest commit hash and promoted to production after successful testing in the development and pre-production environments. A recent production deployment caused the application to fail due to untested integration functionality, requiring a disruptive manual rollback. During the rollback, you noticed many old and unused container images accumulating in Artifact Registry. You need to improve rollout and rollback management and clean up the old container images. What should you do?
Your team is designing a new application for deployment into Google Kubernetes Engine (GKE). You need to set up monitoring to collect and aggregate various application-level metrics in a centralized location. You want to use Google Cloud Platform services while minimizing the amount of work required to set up monitoring. What should you do?
You recently migrated an ecommerce application to Google Cloud. You now need to prepare the application for the upcoming peak traffic season. You want to follow Google-recommended practices. What should you do first to prepare for the busy season?
You are working with a government agency that requires you to archive application logs for seven years. You need to configure Stackdriver to export and store the logs while minimizing costs of storage. What should you do?
Your company recently migrated to Google Cloud. You need to design a fast, reliable, and repeatable solution for your company to provision new projects and basic resources in Google Cloud. What should you do?
Your development team has created a new version of their service’s API. You need to deploy the new versions of the API with the least disruption to third-party developers and end users of third-party installed applications. What should you do?
You need to run a business-critical workload on a fixed set of Compute Engine instances for several months. The workload is stable with the exact amount of resources allocated to it. You want to lower the costs for this workload without any performance implications. What should you do?
You need to create a Cloud Monitoring SLO for a service that will be published soon. You want to verify that requests to the service will be addressed in fewer than 300 ms at least 90% Of the time per calendar month. You need to identify the metric and evaluation method to use. What should you do?
You need to define Service Level Objectives (SLOs) for a high-traffic multi-region web application. Customers expect the application to always be available and have fast response times. Customers are currently happy with the application performance and availability. Based on current measurement, you observe that the 90th percentile of latency is 120ms and the 95th percentile of latency is 275ms over a 28-day window. What latency SLO would you recommend to the team to publish?
You are reviewing your deployment pipeline in Google Cloud Deploy You must reduce toil in the pipeline and you want to minimize the amount of time it takes to complete an end-to-end deployment What should you do?
Choose 2 answers
You are configuring a CI pipeline. The build step for your CI pipeline integration testing requires access to APIs inside your private VPC network. Your security team requires that you do not expose API traffic publicly. You need to implement a solution that minimizes management overhead. What should you do?
You are managing an application that exposes an HTTP endpoint without using a load balancer. The latency of the HTTP responses is important for the user experience. You want to understand what HTTP latencies all of your users are experiencing. You use Stackdriver Monitoring. What should you do?
Your company allows teams to self-manage Google Cloud projects, including project-level Identity and Access Management (IAM). You are concerned that the team responsible for the Shared VPC project might accidentally delete the project, so a lien has been placed on the project. You need to design a solution to restrict Shared VPC project deletion to those with the resourcemanager.projects.updateLiens permission at the organization level. What should you do?
You manage several production systems that run on Compute Engine in the same Google Cloud Platform (GCP) project. Each system has its own set of dedicated Compute Engine instances. You want to know how must it costs to run each of the systems. What should you do?
You are the Operations Lead for an ongoing incident with one of your services. The service usually runs at around 70% capacity. You notice that one node is returning 5xx errors for all requests. There has also been a noticeable increase in support cases from customers. You need to remove the offending node from the load balancer pool so that you can isolate and investigate the node. You want to follow Google-recommended practices to manage the incident and reduce the impact on users. What should you do?
Your organization is running multiple Google Kubernetes Engine (GKE) clusters in a project. You need to design a highly-available solution to collect and query both domain-specific workload metrics and GKE default metrics across all clusters, while minimizing operational overhead. What should you do?
You currently store the virtual machine (VM) utilization logs in Stackdriver. You need to provide an easy-to-share interactive VM utilization dashboard that is updated in real time and contains information aggregated on a quarterly basis. You want to use Google Cloud Platform solutions. What should you do?
You are building and deploying a microservice on Cloud Run for your organization Your service is used by many applications internally You are deploying a new release, and you need to test the new version extensively in the staging and production environments You must minimize user and developer impact. What should you do?
You support a Node.js application running on Google Kubernetes Engine (GKE) in production. The application makes several HTTP requests to dependent applications. You want to anticipate which dependent applications might cause performance issues. What should you do?
You manage your company's primary revenue-generating application. You have an error budget policy in place that freezes production deployments when the application is close to breaching its SLO. A number of issues have recently occurred, and the application has exhausted its error budget. You need to deploy a new release to the application that includes a feature urgently required by your largest customer. You have been told that the release has passed all unit tests. What should you do?
You are managing the production deployment to a set of Google Kubernetes Engine (GKE) clusters. You want to make sure only images which are successfully built by your trusted CI/CD pipeline are deployed to production. What should you do?
You are running a real-time gaming application on Compute Engine that has a production and testing environment. Each environment has their own Virtual Private Cloud (VPC) network. The application frontend and backend servers are located on different subnets in the environment's VPC. You suspect there is a malicious process communicating intermittently in your production frontend servers. You want to ensure that network traffic is captured for analysis. What should you do?
You are investigating issues in your production application that runs on Google Kubernetes Engine (GKE). You determined that the source Of the issue is a recently updated container image, although the exact change in code was not identified. The deployment is currently pointing to the latest tag. You need to update your cluster to run a version of the container that functions as intended. What should you do?
You are using Jenkins to orchestrate your CI/CD pipelines deploying your applications to GKE and on-premises VMs. After expanding your on-premises infrastructure, all resource utilization is normal, but you notice that initiating on-premises deployments is taking longer than expected. You need to accelerate the initiation of on-premises deployments. What should you do?




TESTED 31 Mar 2026