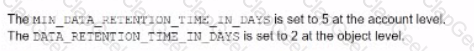When reviewing a query profile, what is a symptom that a query is too large to fit into the memory?
A virtual warehouse's auto-suspend and auto-resume settings apply to which of the following?
User-level network policies can be created by which of the following roles? (Select TWO).
Which account__usage views are used to evaluate the details of dynamic data masking? (Select TWO)
What is a machine learning and data science partner within the Snowflake Partner Ecosystem?
What transformations are supported in a CREATE PIPE ... AS COPY ... FROM (....) statement? (Select TWO.)
What feature can be used to reorganize a very large table on one or more columns?
True or False: A 4X-Large Warehouse may, at times, take longer to provision than a X-Small Warehouse.
A company's security audit requires generating a report listing all Snowflake logins (e.g.. date and user) within the last 90 days. Which of the following statements will return the required information?
What are the default Time Travel and Fail-safe retention periods for transient tables?
A company strongly encourages all Snowflake users to self-enroll in Snowflake's default Multi-Factor Authentication (MFA) service to provide increased login security for users connecting to Snowflake.
Which application will the Snowflake users need to install on their devices in order to connect with MFA?
Which of the following compute resources or features are managed by Snowflake? (Select TWO).
Which of the following indicates that it may be appropriate to use a clustering key for a table? (Select TWO).
A tabular User-Defined Function (UDF) is defined by specifying a return clause that contains which keyword?
Which of the following activities consume virtual warehouse credits in the Snowflake environment? (Choose two.)
What technique does Snowflake use to limit the number of micro-partitions scanned by each query?
How many network policies can be assigned to an account or specific user at a time?
If file format options are specified in multiple locations, the load operation selects which option FIRST to apply in order of precedence?
What is the MINIMUM Snowflake edition required to use the periodic rekeying of micro-partitions?
What statistical information in a Query Profile indicates that the query is too large to fit in memory? (Select TWO).
A data provider wants to share data with a consumer who does not have a Snowflake account. The provider creates a reader account for the consumer following these steps:
1. Created a user called "CONSUMER"
2. Created a database to hold the share and an extra-small warehouse to query the data
3. Granted the role PUBLIC the following privileges: Usage on the warehouse, database, and schema, and SELECT on all the objects in the share
Based on this configuration what is true of the reader account?
How does Snowflake recommend handling the bulk loading of data batches from files already available in cloud storage?
What happens to the shared objects for users in a consumer account from a share, once a database has been created in that account?
A company needs to read multiple terabytes of data for an initial load as part of a Snowflake migration. The company can control the number and size of CSV extract files.
How does Snowflake recommend maximizing the load performance?
Which file format will keep floating-point numbers from being truncated when data is unloaded?
What column type does a Kafka connector store formatted information in a single column?
What service is provided as an integrated Snowflake feature to enhance Multi-Factor Authentication (MFA) support?
Which languages requite that User-Defined Function (UDF) handlers be written inline? (Select TWO).
The bulk data load history that is available upon completion of the COPY statement is stored where and for how long?
A user needs to create a materialized view in the schema MYDB.MYSCHEMA. Which statements will provide this access?
How does Snowflake handle the bulk unloading of data into single or multiple files?
Which operations are handled in the Cloud Services layer of Snowflake? (Select TWO).
Which Snowflake feature will allow small volumes of data to continuously load into Snowflake and will incrementally make the data available for analysis?
Which query profile statistics help determine if efficient pruning is occurring? (Choose two.)
When would Snowsight automatically detect if a target account is in a different region and enable cross-cloud auto-fulfillment?
Which Snowflake feature allows a user to track sensitive data for compliance, discovery, protection, and resource usage?
Which of the following are handled by the cloud services layer of the Snowflake architecture? (Choose two.)
Which of the following is the Snowflake Account_Usage.Metering_History view used for?
Which solution improves the performance of point lookup queries that return a small number of rows from large tables using highly selective filters?
Which metadata table will store the storage utilization information even for dropped tables?
What is the purpose of the STRIP NULL_VALUES file format option when loading semi-structured data files into Snowflake?
Which commands are restricted in owner's rights stored procedures? (Select TWO).
A user wants to access files stored in a stage without authenticating into Snowflake. Which type of URL should be used?
Which Snowflake command can be used to unload the result of a query to a single file?
Which statistics are displayed in a Query Profile that indicate that intermediate results do not fit in memory? (Select TWO).
What feature of Snowflake Continuous Data Protection can be used for maintenance of historical data?
Which data types can be used in Snowflake to store semi-structured data? (Select TWO)
Which command is used to unload data from a Snowflake database table into one or more files in a Snowflake stage?
CREATE STAGE
COPY INTO